








In today’s business environment, success often depends directly on the speed and quality of data processing. That means huge volumes of recorded information — terabytes or even petabytes — that systems must not only deal with on a daily basis but also use to generate near–real-time feedback. For example, video captured by cameras in shopping malls needs to be recognized very quickly to either target customer service or warn security of a potential crime.
Today, software manufacturers offer a variety of Big Data frameworks. We will focus on 5 of the most prominent of these — systems that are relatively mature, that offer good ecosystems and are unlikely to give up their position over the next ten years.
The considered frameworks are developed via open community and available under the Apache License. All are highly scalable and fault-tolerant, provide distributed data processing, can be deployed in clouds, and are managed by Kubernetes.
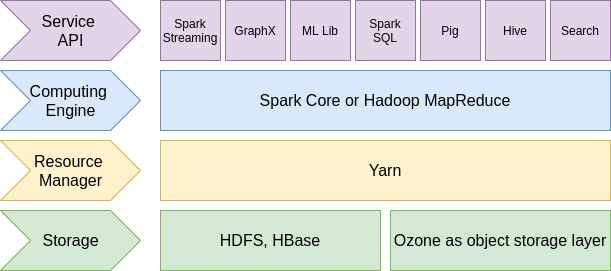
1. Hadoop
Hadoop can be described as a collection of tools, among which is a distributed storage system and a calculation engine designed to handle a large quantity of records. Initially, the data repository was provided on the basis of the Hadoop Distributed File System (HDFS™). However, keeping an eye on recent trends, the team has also proposed Ozone, an object storage layer based on Hadoop Distributed Data Store (HDDS). It is cloud-native, scalable, secure and highly available. Ozone supports protocols such as Amazon S3 and Hadoop File System API.
The first releases of Hadoop offered only MapReduce as a calculation engine. It is able to process data in batch mode, which affects the speed of operation. Thus, the engine can’t be used for real-time computation. However, its performance is quite inspiring: terabytes of data can be processed in minutes, petabytes in hours. Recent Hadoop distributions also include Apache Spark, which can be used instead of MapReduce.
To control resources and schedule jobs, Hadoop provides Yarn (Yet Another Resource Negotiator). This resource manager has become very popular, even among third-party framework developers.
The last, but certainly not least important, Hadoop feature to note is its high fault tolerance, which is achieved by means of redundant node replication and master-slave daemons.
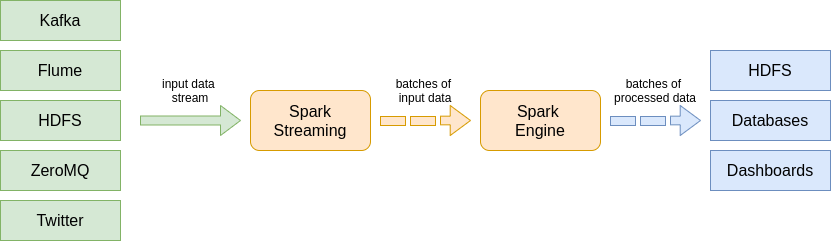
2. Spark
Apache Spark is used mostly to aggregate a huge amount of data and create new views on the basis of that data. It provides a very powerful and useful distributed SQL-query engine. Unlike MapReduce, Spark provides for streaming data processing. In fact, this framework transforms the input stream into a batch chain, runs calculations on it, and then provides an output stream comprising all the batches. This approach allows for close to real-time processing.
Although Spark has been touted to be 100 times faster than MapReduce, we can say this is accurate only for very small jobs. When it is necessary to run complex business tasks, Spark performs about 20 to 25 times better on the same configuration as MapReduce.
This framework doesn’t have its own data storage, but it provides connectors for integration with the most popular repositories. Inside Spark, the input is introduced as Resilient Distributed Datasets (RDDs), which in turn are divided into logical partitions. Actually, it is a read-only collection of records. In case of failure, each partition can be calculated once again without affecting the other parts. Computing tasks can be parallelized on different nodes.
Spark is also considered one of the best frameworks for machine learning applications. Among the best-known products based on it is H2O Sparkling Water.
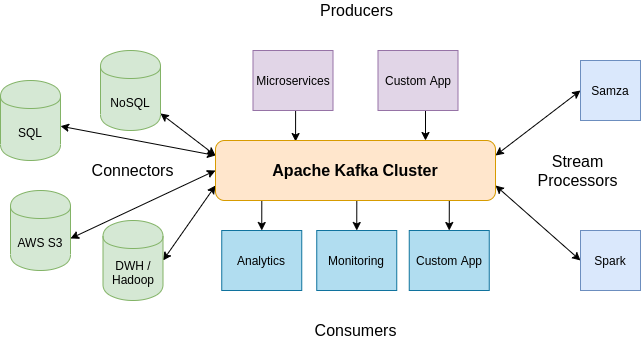
3. Kafka
Does your solution require a high-load message bus to allow microservices to communicate with each other without delays? Kafka can be the right choice for such a task. This platform provides the ability to subscribe to the message queue and publish messages, save data in the reliable repository, and process input streams in real time.
Among others, Kafka provides the following APIs:
- Producer API is used by applications to submit records to Kafka topics.
- Consumer API allows external systems to subscribe to the topics and get data from them.
- Connector API provides the ability to integrate Kafka not only with third-party solutions but also with popular repositories, such as Hadoop, SQL and NoSQL databases, cloud storage systems (e.g. AWS S3), search indexes, and more. For instance, a connector to MySQL can monitor any change made to the recordset.
- Streams API gives access to functionality responsible for transforming data from input streams to output streams. This module not only provides the ability to process a huge amount of data in milliseconds but also ensures great fault tolerance.
Kafka is commonly used in heavily loaded streaming applications that transform input or react to certain events in real time.
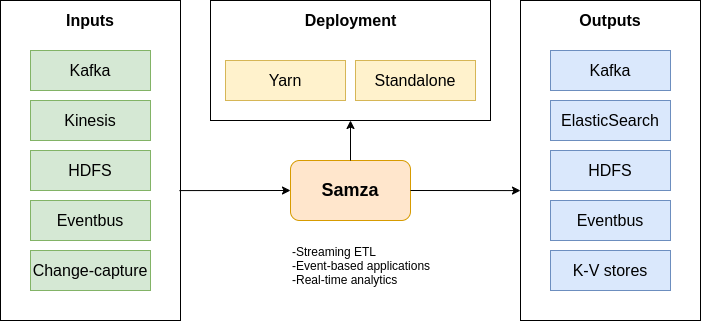
4. Samza
Should your solution be stateful and allow processing data from different sources? It’s possible to integrate Kafka with the Samza framework, which means Kafka will be responsible for records storage, buffering and fault tolerance, while Samsa will take over data processing.
In contrast to MapReduce and even Apache Spark, this framework ensures continuous calculations and output, resulting in response time of less than a second. The stream in Samza is a sequence of multi-user messages, which is partitioned, ordered by sections and reproducible. Samza also keeps the local states during computations. This approach provides additional fault tolerance. To manage resources and tasks, the framework uses Hadoop Yarn.
5. Flink
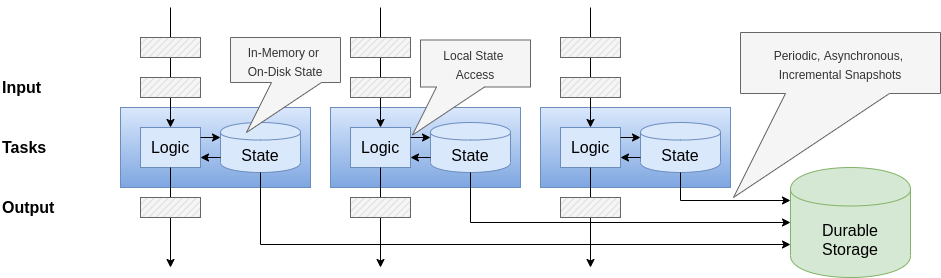
Apache Flink can be thought of as a Spark alternative. This framework is good both for batches and streaming data processing. The applications are divided into thousands of tasks, which are then performed simultaneously in a cluster. Flink can easily maintain a very large application state: its asynchronous and incremental algorithm, based on checkpoints, provides for a very small delay in data processing and ensures state consistency.
Like many computing engines, Flink doesn’t have its own database but rather provides connectors for the most popular repositories. The fault tolerance mechanism continuously creates stream snapshots, which are then kept in reliable storage (e.g. on the main node or HDFS).
Flink processes all operations as real-time applications and supports an arbitrary number of data transformations.
So, what to choose?
All 5 of the above frameworks can be combined in one ecosystem, with the aim of solving specific tasks. The challenge here is to find balance between availability and stability of the system and the complexity of its deployment and maintenance. Our team would be glad to provide you with big data consulting service. In addition, we can migrate your current solution to a new tech stack and improve its performance and fault tolerance.


